By now, you're aware of the fact that the Galaxy S24 line is what brought along Galaxy AI: the set of artificially intelligent features that amazed the world with Circle to Search, Live Translate, and more. Galaxy AI also got Apple to finally come to their senses and make (some) progress in the AI field with their upcoming Apple Intelligence.
One of Galaxy AI's most impressive features is Live Translate – this one literally hears what the speaker is saying and then translates it into your language of preference. The feature arrived with 13 supported languages and recently, three more languages were added, for a total of 16.
I've often wondered how such a thing is made possible – it must've been darn hard to plan and develop it! Samsung confirms my guessing with its latest detailed article on Galaxy AI and the trials and tribulations of the teams around the world behind the project.
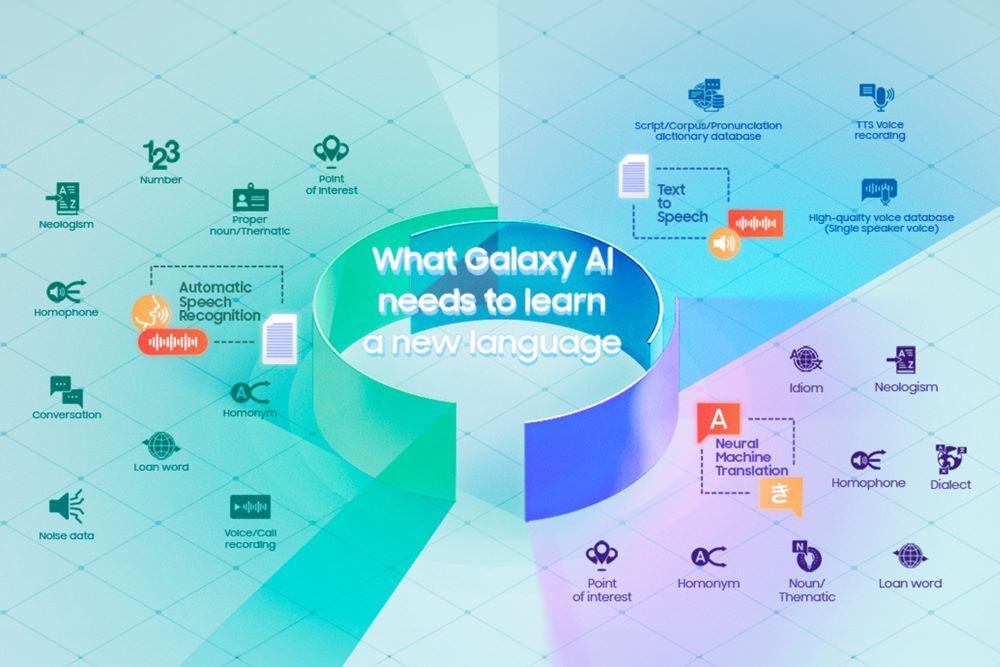
Galaxy AI features such as Live Translate perform three core processes: automatic speech recognition (ASR), neural machine translation (NMT) and text-to-speech (TTS).
Automatic speech recognition (ASR), neural machine translation (NMT) and text-to-speech (TTS) each require distinct sets of information for training. | Image credit – Samsung
How to solve the dialects challenge?
So far, so good: the speech recognition does it thing, then the neural machine translation kick in, then the translated speech is spewed back to you via text-to-speech.
What do you do when the dialects enter the ring, though!?
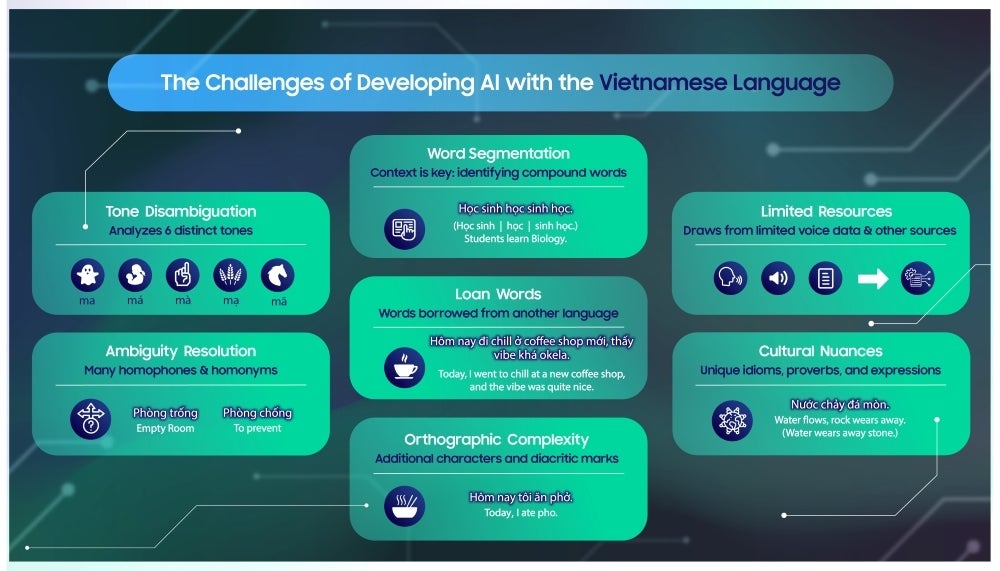
For example, Samsung R&D Institute Vietnam (SRV) faced obstacles with automatic speech recognition models because Vietnamese is a language with six distinct tones. Tonal languages can be difficult for AI to recognize because of the complexity tones add to linguistic nuances. The team responded to the challenge with a model that differentiates between shorter audio frames of around 20 milliseconds.
Then, the Samsung R&D Institute in Poland had the "mammoth hurdle" of training neural machine translation models for a continent as diverse as Europe. Drawing on its extensive experience with projects in over 30 languages across four time zones, the Polish team successfully navigated the challenges of untranslatable phrases and managed idiomatic expressions that lack direct equivalents in other languages.
Recommended Stories
The Samsung R&D Institute from Jordan also didn't have an easy time adapting Arabic – a language spoken across more than 20 countries in about 30 dialects – for Galaxy AI.
Creating a text-to-speech model was no small endeavor, since diacritics and guides for pronunciation are widely understood by native Arabic speakers but absent in writing. Using a sophisticated prediction model for identifying missing diacritics, the team successfully published a language model capable of understanding dialects and responding in standard Arabic.
Each language has a distinct set of qualities that pose challenges in creating an AI language model for it. Tones add to the complexity for tonal languages such as Vietnamese. | Image credit – Samsung
Samsung R&D Institute India-Bangalore teamed up with the Vellore Institute of Technology to gather nearly a million lines of segmented and curated audio data, encompassing conversational speech, words, and commands. This collaboration provided students with hands-on experience on a real-world project and mentorship from Samsung experts. The extensive data collection enabled SRI-B to train Galaxy AI in Hindi, covering over 20 regional dialects along with their unique tonal inflections, punctuation, and colloquialisms.
Local linguistic insights were crucial for developing the Latin American Spanish model, reflecting the language's diversity and its varied user base. For instance, the word for "swimming pool" varies regionally, being "alberca" in Mexico, "piscina" in Colombia, Bolivia, and Venezuela, and "pileta" in Argentina, Paraguay, and Uruguay.
Meanwhile, Samsung R&D Institute China-Beijing and Samsung R&D Institute China-Guangzhou partnered with Chinese companies Baidu and Meitu. They leveraged their experience with large language models, such as ERNIE Bot and MiracleVision, respectively. Consequently, Galaxy AI now supports both Mandarin Chinese and Cantonese, accommodating the primary modes of these languages.
Conversations from coffee shops were also used
Bahasa Indonesia is known for its extensive use of contextual and implicit meanings, which often depend on social and situational cues. To address this, researchers from Samsung R&D Institute Indonesia conducted field recordings in coffee shops and work environments, capturing authentic ambient noises that could distort input. This helped the model learn to extract essential information from verbal input, thereby enhancing the accuracy of speech recognition.
Japanese, with its limited number of sounds, has many homonyms that must be interpreted based on context. To tackle this challenge, Samsung R&D Institute Japan utilized Samsung Gauss, the company's internal large language model, to create contextual sentences with scenario-relevant words and phrases. This approach helped the AI model distinguish between different homonyms effectively.
Homonyms are words with different meanings that are either homographs (words that have the same spelling) or homophones (words that have the same pronunciation), or both.
AI is really complex – and I can't even imagine what the future holds in this particular field.
Did you enjoy reading this article?
There's more to explore with a FREE members account.
Sebastian, a veteran of a tech writer with over 15 years of experience in media and marketing, blends his lifelong fascination with writing and technology to provide valuable insights into the realm of mobile devices. Embracing the evolution from PCs to smartphones, he harbors a special appreciation for the Google Pixel line due to their superior camera capabilities. Known for his engaging storytelling style, sprinkled with rich literary and film references, Sebastian critically explores the impact of technology on society, while also perpetually seeking out the next great tech deal, making him a distinct and relatable voice in the tech world.
A discussion is a place, where people can voice their opinion, no matter if it
is positive, neutral or negative. However, when posting, one must stay true to the topic, and not just share some
random thoughts, which are not directly related to the matter.
Things that are NOT allowed:
Off-topic talk - you must stick to the subject of discussion
Offensive, hate speech - if you want to say something, say it politely
Spam/Advertisements - these posts are deleted
Multiple accounts - one person can have only one account
Impersonations and offensive nicknames - these accounts get banned
Moderation is done by humans. We try to be as objective as possible and moderate with zero bias. If you think a
post should be moderated - please, report it.
Have a question about the rules or why you have been moderated/limited/banned? Please,
contact us.









Things that are NOT allowed: